Python is very powerful for web scraping. So, let’s scrape a website.
Scraping relies heavily on the website’s structure (div, class names, etc). But, websites tend to change their structure overtime. So, in this tutorial we will use a sandbox website that is made specifically for scraping practice, scrapethissite.com which provides a list of countries for you to scrape.
I’ll show you how to scrape a website and also my thought process to scrape and solve problems I faced during the process of writing the scraping code.
Purpose / Overview
The purpose of this code is the scrape and extract the countries data from the website mentioned before and export it into CSV.
This is a basic tutorial for beginners. It doesn’t include dealing with pagination and dealing with securities like CAPTCHA. Those will be taught in later tutorials.
Libraries
So, we’ll need to use a few libraries that will be really helpful to scrape a website :
- lxml – to access XML
- urllib – to open the website
- csv – to export the data into CSV
Remember to install the libraries with pip install [library name] before writing the code.
Now, we’ll dive into the code starting with determining the variables.
Don’t forget to import the libraries we’ll use.
import csv
from lxml import html
from lxml.etree import XPath
from urllib.request import Request, urlopenVariables
Let’s determine the variables that will be important for the scraping process.
url = "https://www.scrapethissite.com/pages/simple"
columns = ['name', 'capital', 'population', 'area'] #the table headers
dataSet = [] #will be exported to csvAccess the Website
Now, let’s access the website.
Normally, you can access a website with this code.
source = html.parse(url).getroot()But, some websites blocked it since they can’t verify where the scraper is from. So, to solve that, we have to state a verified user agent (in this case, Mozilla) with the help of request library and then open it with html.parse().
req = Request(
url='https://www.scrapethissite.com/pages/simple',
headers={'User-Agent': 'Mozilla/5.0'}
)
source = html.parse(urlopen(req))XPath
This is a very important part as it determines where you extract the data you want from.
The main challenge of web scraping is converting an unstructured data to a structured one. Lucky enough, this practice website has a good structure so it’s not too hard for us to scrape.
Let’s identify the XPaths we need. It’s similar to CSS.
I’ll divide the XPaths we need into 2 categories :
- Container : It’s like the parent element
- Elements : the actual element we want to extract data from
Let’s first identify the container. It’ll be the parent element where all the data we want to scrape resides. In this case, it’s a div with the class col-md-4 and country.
To help with identifying the XPath, you can use inspect element and copy XPath like how I did in the image below.
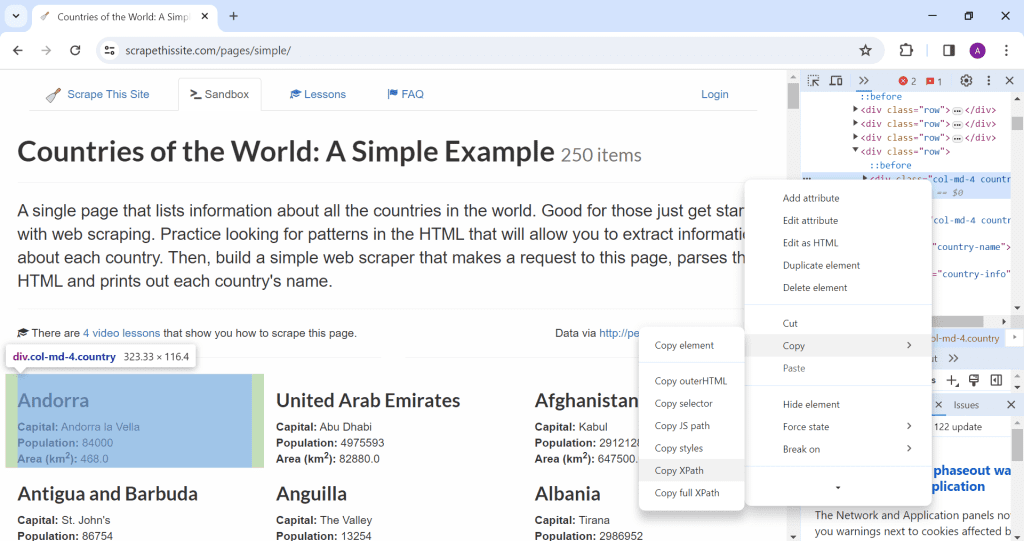
But, the result is not too accurate. Actually, the result is too specific addressed to the element we inspected. What we want is an XPath generic enough that we can scrape each element. Later, we’ll loop through each element to get the data. If the XPath is too specific, we’ll only scrape the same data. For example, we’ll get 200 rows of the same data. We want to avoid that by using a more generic XPath.
This is the result
//*[@id="countries"]/div/div[4]/div[1]And what we want is
//div[@class="col-md-4 country"]Now that we’ve identified the container, let’s identify the elements we want inside.
Following the XPath pattern before, we can can use the element’s classes. We’ll also add . at the start of each XPath to tell that they’re inside the parent element.
These are the element XPaths
namePath = XPath('.//h3[@class="country-name"]')
capitalPath = XPath('.//div[@class="country-info"]/span[@class="country-capital"]')
populationPath = XPath('.//div[@class="country-info"]/span[@class="country-population"]')
areaPath = XPath('.//div[@class="country-info"]/span[@class="country-area"]')Looping
Now that we’ve determined where the elements are located, the scraping is actually pretty simple. We’ll just be looping through each container and extract the elements’ texts.
for country in countries(source):
name = namePath(country)[0].text_content().strip()
capital = capitalPath(country)[0].text_content()
population = populationPath(country)[0].text_content()
area = areaPath(country)[0].text_content()
dataSet.append([name, capital, population, area])varPath(var) returns an array so we have to access the 0th index to get the text content and strip it to remove whitespace.
Then, we’ll append it to the dataset.
Exporting to CSV
Usually, the main purpose of web scraping is to collect data that will be used for data science and Machine Learning.
And, usually, the preferred format for the data is CSV.
So, we’ll export the dataSet to CSV.
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'countries.csv', columns)And, we’re done. We’ve scraped a website! Congratulations!
Full Code
import csv
from lxml import html
from lxml.etree import XPath
from urllib.request import Request, urlopen
url = "https://www.scrapethissite.com/pages/simple"
columns = ['name', 'capital', 'population', 'area']
dataSet = []
req = Request(
url='https://www.scrapethissite.com/pages/simple',
headers={'User-Agent': 'Mozilla/5.0'}
)
source = html.parse(urlopen(req))
countries = XPath('//div[@class="col-md-4 country"]')
namePath = XPath('.//h3[@class="country-name"]')
capitalPath = XPath('.//div[@class="country-info"]/span[@class="country-capital"]')
populationPath = XPath('.//div[@class="country-info"]/span[@class="country-population"]')
areaPath = XPath('.//div[@class="country-info"]/span[@class="country-area"]')
for country in countries(source):
name = namePath(country)[0].text_content().strip()
capital = capitalPath(country)[0].text_content()
population = populationPath(country)[0].text_content()
area = areaPath(country)[0].text_content()
dataSet.append([name, capital, population, area])
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'countries.csv', columns)Conclusion
Now, you’ve understood how to scrape a website with python and lxml.
To solidify this newly learned skill, I suggest you try scrape a different website on your own with this knowledge.
Remember, there’s no one key fits all as each website has a different structure. So, you have to modify the code according to the website you want to scrape.
You’ll learn a lot through the various challenges and problem solving.
Happy scraping!